
فایل robots.txt یک فایل متنی است که وب مستر ها آن را می سازند تا به ربات های وب (ربات های موتورهای جستجو) بگویند چگونه صفحات سایت را کرال (Crawl) کنند. فایل robots.txt بخشی از پروتکل منع کردن ربات ها (robots exclusion protocol) است که شامل گروهی از استانداردهای وب می شود که به ربات ها می گوید چگونه صفحات وب را کرال کنند، به محتوا درسترسی پیدا کنند و آن را ایندکس کنند و آن محتوای را در اختیار کاربر قرار دهند. در ادامه، توضیحات کاملی در خصوص فایل robots.txt را در اختیار شما قرار می دهیم.
فایل robots.txt چیست؟
در عمل، فایل robots.txt تعیین می کند که آیا کاربران خاص (نرم افزار کرال وب) بتوانند یا نتوانند بخشی از وب سایت را کرال کنند. فرمان های این فایل به صورت اجازه دادن (Allowing) یا اجازه ندادن (Disallowing) یک سری رفتار خاص عمل می کنند.
فرمت بیسیک فایل robots.txt:
[User-agent: [user-agent name [Disallow: [URL string not to be crawled
ترکیب این دو خط با هم یک کد کامل robots.txt محسوب می شود. امّا ممکن است خط های فرمان مختلفی به این فایل اضافه شود.
درون یک فایل robots.txt هرکدام از فرمان های user agent به عنوان یک دسته جداگانه لحاظ می شوند که با یک فاصله یک خطی از هم جدا می شوند.
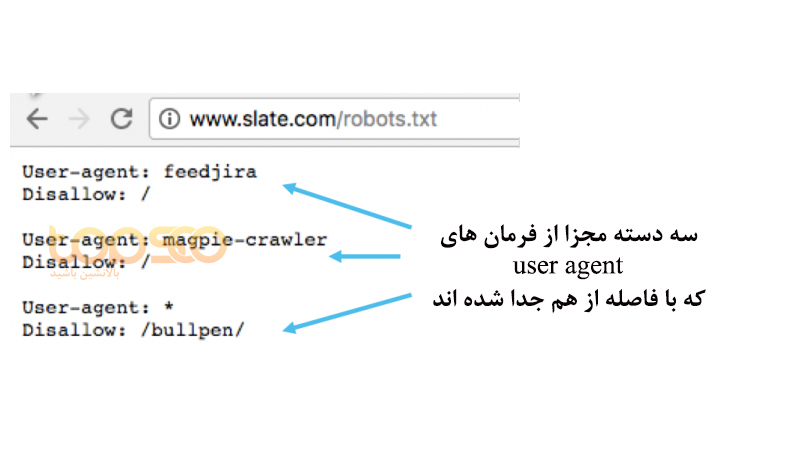
توجه داشته باشید که در فایل هایی که چند خط دارند، هر قانون allow یا disallow فقط بر user agent خاصی که در آن خط آمده اعمال می شود. اگر فایل حاوی قانونی باشد که به بیش از یک user agent بر می گردد، کرالر فقط به فرمانی توجه می کند که جزئیات بیشتری داشته و دقیق تر باشد.
واژگان فنی فایل robots.txt
robots.txt فایلی است که زبان خاص خودش را دارد. در این فایل پنج اصطلاح رایج وجود دارد که ممکن است به آن ها بر بخورید:
- User-agent: وب کرالر مشخصی که شما دستورات کرال را به آن می دهید (معمولا یک موتور جستجو است). لیست User agent های مختلف را می توانید در سایت robots.txt ببینید.
- Disallow: فرمانی است که به User agent می گوید آدرس خاصی را کرال نکند. برای هر URL تنها یک خط “:Disallow” مجاز است.
- Allow (قابل استفاده تنها برای ربات گوگل): دستوری که به گوگل بات می گوید می تواند به صفحه یا یک ساب فولدر خاص دسترسی داشته باشد در صورتی که صفحه یا ساب فولدر سطح بالاتر آن disallow شده است.
- Crawl-delay: تعیین اینکه که کرالر یا خزنده باید چند ثانیه قبل از بارگذاری و کرال محتوای صفحه صبر کند. توجه داشته باشید که گوگل بات ممکن است این فرمان را نشناسد امّا نرخ کرال را می توان در سرچ کنسول گوگل مشخص کرد.
- Sitemap: برای فراخوانی موقعیت هر فایل XML سایت مپ مرتبط با URL مدنظر استفاده می شود. توجه داشته باشید که این فرمان فقط توسط Google، Ask، Bing و Yahoo پشتیبانی می شود.
مثال هایی از فایل robots.txt
در ادامه نمونه هایی از فایل robots.txt برای وب سایت فرضی www.example.com را برای شما فراهم کرده ایم:
آدرس فایل robots.txt:
www.example.com/robots.txt
بلاک کردن تمام خزنده های وب از دسترسی به تمام محتوا
* :User-agent / :Disallow
استفاده از این فرمان به تمام خزندگان وب می گوید تا هیچ صفحه ای را در سایت www.example.com کرال نکنند.
اجازه دسترسی به تمام صفحات به تمام خرنده های وب
* :User-agent :Disallow
استفاده از این فرمان به تمام خزندگان وب می گوید تا تمام صفحات سایت www.example.com را کرال کنند.
بلاک کردن یک خزنده وب مشخص از دسترسی به یک فولدر مشخص
User-agent: Googlebot /Disallow: /example-subfolder
این فرمان به خزنده گوگل می گوید که هر صفحه ای که حاوی رشته /www.example.com/example-subfolder است را کرال نکند.
بلاک کردن یک خزنده وب مشخص از یک صفحه وب مشخص
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
این فرمان به خزنده Bing می گوید که صفحه www.example.com/example-subfolder/blocked-page را کرال نکند.
فایل robots.txt چگونه کار می کند؟

موتورهای جستجو دو نقش عمده دارند:
- کرال کردن وب برای پیدا کردن محتوا
- ایندکس کردن آن محتوا برای نمایش دادن به کاربری به دنبال آن اطلاعات است
برای کرال کردن سایت ها، موتورهای جستجو لینک ها را دنبال کرده تا از یک سایت به سایت دیگر بروند و نهایتا میلیاردها لینک و وب سایت را کرال می کنند. این فرآیند کرال کردن گاهی با نام رفتار عنکبوتی یا Spidering نیز شناخته می شود.
بعد از رسیدن به یک وب سایت و قبل از اسپایدر کردن آن، خزنده به دنبال فایل robots.txt خواهد گشت. اگر پیدا کند، خزنده قبل از اینکه به خزیدن صفحه ادامه دهد، آن فایل را می خواند. از آن جایی که این فایل حاوی اطلاعاتی در مورد این است که چگونه موتور جستجو باید کرال کند، دستورالعمل هایی که آن جا وجود دارد، فعالیت های خزنده در آن سایت را تعیین خواهد کرد. اگر فایل robots.txt شامل فرمانی نباشد که user agent را منع کند، خزنده به کرال کردن سایر اطلاعات سایت ادامه خواهد داد.
فایل robots.txt در کجای سایت قرار می گیرد؟
هر زمان که یک خزنده به سایت شما سر می زند، می داند که باید اول به دنبال فایل robots.txt بگرد. ولی آن ها تنها در یک جای مشخص به دنبال این فایل خواهند گشت: دایرکتوری اصلی (دامنه اصلی یا صفحه خانه شما).
اگر یک user agent به مسیر http://www.example.com/robots.txt سر بزند و فایل را در آنجا پیدا نکند، فرض را بر این می گذارد که سایت این فایل را ندارد و به کرال کردن بقیه صفحه و شاید حتی کل سایت ادامه خواهد دارد. در نتیجه حتی اگر فایل در مسیر های example.com/index/robots.txt یا www.example.com/homepage/robots.txt موجود بوده باشد، توسط user agent پیدا نخواهد شد و در نتیجه با سایت به نحوی برخورد می شود که اصلا این فایل را ندارد.
برای این که مطمئن شوید این فایل همیشه توسط خزنده ها پیدا می شود، مطمئن شوید که آن را در دایرکتوری اصلی یا دامنه اصلی (root domain) قرار داده اید.
چرا وجود فایل robots.txt ضروری است؟
فایل robots.txt دسترسی خزنده های وب را به بخش های مختلف سایت شما کنترل می کند. اگر شما به صورت تصادفی ربات گوگل را از کرال کردن کل سایتتان disallow بسیار خطرناک خواهد بود ! ولی مواردی وجود دارد که استفاده از این فایل بسیار کاربردی خواهد بود.
برخی از عمده ترین موارد استفاده از این فایل شامل موارد زیر می شوند:
- جلوگیری از به نمایش درآمدن محتوای تکراری در نتایج جستجوی گوگل (توجه داشته باشید که برای این مورد متا ربات های گزینه بهتری هستند).
- شخصی نگه داشتن یک بخش کامل از وب سایت.
- جلوگیری از به نمایش درآمدن صفحات جستجوی داخلی در نتایج جستجوی عمومی.
- مشخص کردن مسیر سایت مپ.
- جلوگیری از ایندکس شدن فایل های مشخص (تصویر، PDF و غیره) توسط موتورهای جستجو.
- مشخص کردن Crawl delay یا تاخیر در کرال برای جلوگیری از بار زیاد سرورها وقتی که خزنده ها چند بخش از محتوا را یک جا لود می کنند.
اگر هیچ بخشی در سایت شما وجود ندارد که بخواهید دسترسی user agent را در آن کنترل کنید، می توانید اصلا از فایل robots.txt استفاده نکنید.
چگونه بفهمیم که سایتمان فایل robots.txt دارد؟
در صورتی که مطمئن نیستید سایتتان فایل robots.txt دارد یا نه می توانید به سادگی دامنه اصلی خود را تایپ کرده و سپس /robots.txt را به انتهای URL اضافه کنید. به عنوان مثال، robots.txt سایت تاپ سئو در مسیر https://www.topseo724.com/robots.txt قرار دارد.
اگر این مسیر برای شما نتیجه ای را نمایش ندهد، شما در حال حاضر فایل robots.txt ندارید.
چگونه فایل robots.txt بسازیم؟
اگر به این نتیجه رسیدید که سایت شما فاقد robots.txt است و یا می خواهید فایلی که دارید را تغییر دهید، می توانید طی چند مرحله ساده این کار را انجام دهید. برای این کار می توانید دستورالعمل گوگل برای ساخت robots.txt را دنبال کنید و با ابزار تست robots.txt مطمئن شوید که فایل به درستی قرار گرفته است.
نکاتی در مورد فایل robots.txt و سئو سایت
استفاده از robots.txt برای سئو سایت اهمیت دارد و رعایت کردن نکات زیر ضروری است تا این فایل آسیبی به سئو سایت وارد نکند:
- مطمئن شوید که هیچ بخشی از وب سایت که مایل هستید کرال شود را بلاک نکرده اید.
- لینک های موجود در صفحه ای که بلاک کرده اید دنبال نخواهند شد.
- از فایل robots.txt برای جلوگیری از به نمایش در آمدن اطلاعات حساس (اطلاعات حساب شخصی) در نتایج جستجو استفاده نکنید. زیرا ممکن است سایر صفحات به آن صفحه حاوی اطلاعات حساس لینک دهند و در نتیجه فایل robots.txt را دور بزنند. اگر می خواهید این صفحه را بلاک کنید از روش های دیگری مانند استفاده از پسورد یا فرمان noindex استفاده کنید.
- بعضی از موتورهای جستجو چندید user agent دارند. به عنوان مثال گوگل از گوگل بات برای سرچ ارگانیک و از Google bot-image برای تصاویر استفاده می کند. بیشتر user agent هایی که متعلق به یک موتور جستجو هستند از قواعد یکسانی پیروی می کنند، به این ترتیب نیازی نیست برای تک تک آن ها فرمان جداگانه ای نوشت.
- یک موتور جستجو محتوای فایل robots.txt شما را کش خواهد کرد و حداقل روزی یک بار این کس را آپدیت می کند. اگر فایل را تغییر داده اید و می خواهید آپدیت آن سریع تر انجام شود، می توانید URL فایل خود را در گوگل ثبت کنید.